
It has been a while since I wanted to put my hands on the Go programming language. The reasons were many. The programming language I am more used to is PHP which is quite at the bottom of the reputation scale for a programming language, and Go is quite on the other end. Job offers based on Go offer in general quite more money, and hey it's supposed to be fast, easy, and above everything else, cool. The most important factor.
And now it has been a while since I got the chance to use it in a professional project. Of course, when learning something new, you're not very good at it immediately, leading to a degree of frustration that might transpire in this blog post.
Still, let's begin with the cool parts and the reasons I wanted to use Go in the first place. Go is a compiled language (statically typed) and it offers custom types.
The advantages of having a compiler are plenty, enough to even start the term CDD, compiler driven design, which is a short-sight vision about software development - you cannot rely solely on the compiler to tell you you're doing a good job, or else you are missing more than half of the picture- , but nevertheless it is there and unavoidable.
Your code needs to compile, and that's the first safety measure for your work. A safety measure that doesn't exist in the non compiling languages. You can do refactors, change names of variables, files, classes, directory structure, and you'll be safe with the compiler. With non compiling languages you either have a very extensive test suite, or you will deploy stupid bugs to production - oh I forgot to change the import on that file!-. That Go is statically typed is part of the same feeling of safety that the compiler gives you.
But what about the difficult parts?
Value Objects
I always apply DDD patterns in my projects. While it might seem that DDD is only valid for Object Oriented languages, it's actually language agnostic, you can even have DDD with functional programming, - there's a book about that!-. It's just a matter of applying the patterns properly. Of course, with OO languages, it's just easier, especially for the tactical patterns.
Value objects are a building block for any program. They explain the domain and have a couple of features that gives you that security that the compiler can give you: they are immutable, and they can't be in an invalid state.
Unfortunately, both things are very hard to ensure with Go, not to say impossible.
Let's take an Value Object that represents an email address. We can think of several way to implement that with Go, let's begin with the simplest, a type alias:
type Email string
That would be an awesomely fast way to implement a value object, but nothing stops anybody to do that
var myEmail Email = "invalid-email"
We have an invalid VO in memory. Not good. Let's improve it by:
type Email string
func NewEmail(input string) Email {
// email validation, PHP has some build in function for that
if invalid {
panic("Invalid Email")
}
return Email(input)
}
Now we have a typical constructor, common in the Go community, for our email VO. That's better, but we are still leaving the possibility for a programmer to instantiate an invalid email:
validEmail := NewEmail("john.do@gmail.com") //first option
invalidEmail := Email("invalidEmail") // second option, bad
How do we force the future programmers, which all of them will go through a junior phase, to always use the first option and never the second?
Somebody might say that it is common in Go to find those constructors function, so if you see them, you should use them. But that's not good. We're relying that the programmer will know that, and that's surely not always going to be the case.
So a real way to solve it is by making the email type private:
type email string
func NewEmail(input string) email {
// email validation, PHP has some build in function for that
if invalid {
panic("Invalid Email")
}
return email(input)
}
(why the distinction is made by upper case or lower case defies my understanding)
That way we force future programmers to always use the function, since they can't access the type directly. Our clients - the programmers using our code- will have less chances to misuse it.
But it doesn't come with it's own inconveniences. Value Objects are normally pieces of entities. For example, we can have our entity customer that has this email:
type Customer struct {
name string
email email
}
if we want to use the type, Customer must be declared in the same package. That means it should be at least in the same directory:
└── customer
├── customer.go
└── email.go
That in general is a desired outcome. Everything good, except, that value objects might be shared with other entities or aggregate roots.
First of all, let me argue that we should never use primitives such as string, int, etc in our domain. The domain can be enriched by just changing a string type to customerName type. Getting used to it will help avoiding bugs and actually develop faster. Not even booleans should be there, there's always a real meaning in the domain, always a value object.
That applies of course to ID types. It's clearer to see customerId than uuid. That's important, because if you happen to have more than one aggregate root in your project, and there's a reference, that reference must be by Id. From Implementing Domain-Driven Design:
Rule: Reference Other Aggregates by Identity
(from the aggregate root chapter. This whole section is worth a re-read every now and then).
In practical terms, that means that if we have another aggregate that references customer that aggregate root will need the ID type available. For example, we want to model a purchase like another aggregate root and it references to our customer:
type Purchase struct {
id purchaseId
customerId customerId
...
}
we are using this private customerId type here. What that means is that either Purchase and Customer code have to be placed in files in the same directory, so they belong to the same package:
└── sales
├── customer.go
├── email.go
└── purchase.go
That again can be desirable, but at some point it might force to some weird mixture of files in the same folder (and double it with the test files).
There's a bigger problem with a type alias. We can perfectly do that:
var c Customer
c.Email = ""
The above compiles, because we are just using a type alias. That's quite disturbing, we can bypass both the constructor and the type, so to avoid this here's another implementation:
type email struct{
value string
}
func NewEmail(input string) email {
// email validation, PHP has some build in function for that
if invalid {
panic("Invalid Email")
}
return email{value: input}
That is probably the best implementation of a value object, even though it's too much lines of code. Still that doesn't the two evils:
I hope that the whoever is going to use my code is going to look for and use the "NewXX" constructor functions
I place all the domain in the same directory having a lot of files there.
The balance for me is actually to go for #1 for ID value objects, and #2 for all the rest, having IDs in each place, it means I can separate in a logical way the directories with domain concepts.
You could argue that the focus for a Go project should be smaller, just a single aggregate root for example. That might be the solution. If modeled properly, aggregate roots, following the rules from the book above, they should be so independent it shouldn't matter if they are deployed independently with their own infrastructure or together on a bigger service.
But either you have the deploy problem very solved and very consistent so it's easy to go for such small aggregates or you'd better stick with slightly bigger services. A service that has a full bounded context is the proper boundary for my taste, and that often means more than one aggregate root, and the luxury of not having to think about infrastructure used to communicate services (namely any message broker). Just have the independence coded "virtually", it can always use implementation with real infrastructure behind, if you change your mind.
Going a single aggregate root is still OK, but beware of going further, just deploying a part of the aggregate root, for example a consumer to generate a projection, or a consumer that reacts to some domain events. Then you might loose sight of the big picture - or just small picture!- . I believe this practices to deploy parts that belong to an aggregate root, but not deploying it fully is the cause of the movement pushing for monorepos or even to go away from microservices - as then they are understood as those incomplete parts. Go kind of pushes you to this direction. Just be careful.
Error handling
Go has a very specific way to deal with errors. Functions can return lists of values, and so one of them is the error. The compiler forces you to use all return values when calling a function, so that's actually cool, you don't forget to treat the error cases, at the very early stages of developing.
But it doesn't come with its own set of problems. For instance, let's make the function above to return both email and error:
func NewEmail(input string) (email, error) {
// email validation, PHP has some build in function for that
if invalid {
return ??, errors.New("invalid input")
}
return email(input), nil
}
// extra function to prove the points:
func EmailDomain(input email) string {
parts := strings.Split(string(input), "@")
return parts[1]
}
The first problem, what do we return in the case of error? what the book "Learning Go: An Idiomatic Approach to Real-World Go Programming" would say is to return a zero value (yes, I always buy and read books related to the subject). return email(""), errors.New("invalid input"), that is an invalid value object - well, of course, we are returning error!- but just the fact that we have to code an invalid value object tells that something is wrong! It is so easy to think that you've got it!:
email, err := NewEmail("wrongemail.com")
domain := EmailDomain(email) // this is going to break!
Of course you always, always, always, need to check the error:
email, err := NewEmail("wrongemail.com")
if err != nil {
// you are forced to think about this case now, which is good.
}
domain := EmailDomain(email)
I would say this is bad UX for a programming language, not really intuitive. Why? You have to learn how to do it properly, and there's no way from the "API creator" (me) to make sure that a junior programmer won't mess this, unless this junior is not that junior anymore and knows how's that suppose to be.
And that gives for another weird common in Go projects. From the same book Learning Go: An Idiomatic Approach to Real-World Go Programming:
Don't write fragile programs. The core logic for this example is relatively short. Of the 22 lines inside the for loop, 6 of them implement the actual algorithm and the other 16 are error checking and data validation. You might be tempted to not validate incoming data or check errors, but doing so produces unstable, unmaintainable code. Error handling is what separates the professionals from the amateurs.
I am not going to argue with the point made here. I just want to point out that the way of being professional with Go is to hide your core logic that amounts to 25% of the code, with 75% of error handling code that looks like this:
if err != nil {
xxxx
}
That's a nice way to add distractions when reading the code. Something that we do 90% of the time. As opposed to 10% of the time of just writing it. Your mind really starts ignoring those ifs when you read the code. It's like those people that live next to a train station and they get "immune" to the train's sounds and they don't hear it anymore. Unfortunately it seems that they are more likely to be hit by a train for the very same reason. I hope I won't get hit by this train.
Domain Events
Domain events is also a tough bone. Domain Events are representations of things that happened in the domain. Like Value Objects they should be immutable: as far as I know, the past cannot be changed. In some auditable systems based on this pattern the edition of domain events will lead to legal issues.
And like value objects, and actually, like everything in your code, it would be interesting that they cannot be instantiated with an invalid state. This last part we've seen is quite hard to achieve, and we find similar problems as the value objects above.
Let's see that clear with an example.
type customerRegistered struct {
eventId uuid.UUID
occurredOn time.Time
customer Customer
}
func NewCustomerRegistered(c Customer) customerRegistered {
return customerRegistered{
eventId: uuid.New()
occurredOn: time.Now()
customer: c
}
}
That would be desired, first of all, everything is private, so only this package can use this. It makes sense since the domain event belongs to this aggregate root, customer. We can go further and make the constructor private, since only one place should be responsible of producing the domain events related to the aggregate root:
package customers
func newCustomerRegistered(c Customer) customerRegistered {
...
}
func RegisterCustomer(cId CustomerId, e email) (Customer, customerRegistered) {
c := Customer{id: cId, email: email}
de := newCustomerRegistered(c)
return c, de
}
Since GO forces to use all the return values from a function, I really like this way of creating domain events, whenever me of the future or somebody else registers a user will be reminded that a domain event is also created at the same time.
But is it true that the domain event is going to be used only in this package? Probably we will have event handlers that react whenever this event happens, the signature of the handling function will need the domain event type:
type DoXOnCustomerRegisteredEventHandler struct {
repo RepoInterface
}
func ( h DoXOncustomerRegisteredEventHandler) handle(event CustomerRegistered) error {
//execute domain logic
return nil
}
we need to use the type. There's no other way around it, interfaces won't help - we'll still need to make sure that the actual value is of that concrete type for this event handler-. And that leads us to the same place: we either make the type public, or we have to place all the handlers in the same package, meaning, the same directory.
Handlers shouldn't be placed in the same package. Handlers are the clients of the Domain and should be only allowed to executethe domain in the only way that the domain allows it. Basically using its "interface". If we place it in the same package, we are hoping, again, that the next developer maintaining the code will know some stuff that he/she would have no reason to know, that the handler is not supposed to use any of the other stuff found in the same package.
In this case, I really prefer to make the domain event public. The worst things that we are allowing is that:
package customerHandlers
func BadStuff() {
var badDE1 CustomerRegistered // complete invalid state
badDE2 := CustomerRegistered{} // complete invalid state
}
I think this is the minimum evil, and actually, how the hell is Go supposed to allow the declaration of a variable of a specific type? I do wish it forced always through the creator but it's asking too much. I just need to get to used to it.
but having all the attributes private inside at least ensures immutability, modifications like this: badDE1.occurredOn = time.Now() won't be possible, which is good.
Immutability
Both Value Objects and Domain Events should be immutable. In general immutability is good, everywhere, it might give some extra lines of code, but totally worth it.
For Value Objects above, we are forcing immutability by the package visibility rules
package otherThanEmailPackage
email := NewEmail("validEmail@gmail.com")
// we could "edit" the email, but at practical terms is like
// creating a new email. We throw the old value to teh trash and
// start brand new.
email = NewEmail("validEmail2@gmail.com")
For structs (so far we've seen you can implement both aggregate roots and domain events with structs) we use the same trick. Having the attributes private:
package customers
type Customer struct {
id CustomerID
name string
email email
}
type customerRegistered struct {
eventId uuid.UUID
occurredOn time.Time
customer Customer
}
This way we ensure immutability, at least outside from our package. But again, what happens when things are private? That only this package is able to read those attributes. Do we need to do that outside of the package?
For aggregate roots like customer a very possible place where we need to read those values are in repository implementations, or else how are we supposed to persist those in any database? In that case, we need some getters, ugh. The Learning Go: An Idiomatic Approach to Real-World Go Programming book says otherwise:
One final note: do not write getter and setter methods for Go structs, unless you need them to meet an interface [..]. Go encourages you to directly access a field. Reserve methods for business logic. The exceptions are when you need to update multiple fields as a single operation or when the update isn't a straightforward assignment of a new value
Let's not not focus on setters. But on getters. It's saying that we should access fields directly. That means making all the attributes public. Again I need to trust the me of the future and other developers that won't mess it. Another thing to know beforehand.
The setters part is more scary - I would argue a setter should never exist, there's always a domain concept that explains better what's happening than setXX -, suddenly the users of my code can just edit my entity without using any of the methods I am adding that careful check the business rules? Suddenly the surface of the interface of my module grew by a function for each field of my entity! And it's a surface I don't even want it to exist! I don't want any user to set any different customerID, or email or whatever, unless it's not by using the methods I am carefully developing that check all the business rules!
But here I go for making the fields public, and again hoping that the future developer is a good developer, since I can't be.
On the other hand, it might be useful to be able to bypass some business rules. For instance, with repositories, we can instantiate the fetched entity from the database directly, without having to call the constructor (we might need to call all the constructors for all the VO if we kept them private above). If it has been previously saved in the DB that means it was OK right? Well we might have developed a new feature that added a new field, which is mandatory, and now the fetched entity, old one, doesn't have this field, so if we then make it go through a process that needs this field, this will break, and that might be harder to debug than simply breaking when fetching the entity. (You can think of several ways about how to solve this issue - should be at the time of coding the new feature.).
For Domain Events, the usual case is that you want to marshall them - whether you are sending them through any bus, persist them in the database, or use any kind of infrastructure, the shape they will take will be a serialized one. If you use the typical marshallJSON functions, you will need to make the attributes public, so we have the same problem as above.
The difference with domain events is that we will never want to edit them, as opposed to aggregate roots. So for domain events something like a readonly mark for a field would be very useful. We would be able to keep the field public. But from the Learning Go: An Idiomatic Approach to Real-World Go Programming book
As we'll see in the next chapter, there are no immutable arrays, slices, maps or structs, and there's no way to declare that a field in a struct is immutable. This is less limiting than it sounds. Within a function, it is clear if a variable is being modified, so immutability is less important. In "Go is call by value" we'll see how Go prevents modifications to variables that are passed as parameters to functions.
What the above wants to say is that most of the time, if you modify stuff, you are modifying a copy, that will then be discarded, the way to avoid that is to use pointers. That's why aggregate roots should have methods with pointer receivers to edit them.
But still this is quite contradictory with the quote above where it encourages you to edit directly the fields of a struct:
func (h EventHandler) handle(de DomainEvent) error {
c := h.repo.find(de.Id) // that returns a pointer to a customer
var invalid CustomerId // until now, the Ids are the ones I stil keep public
c.Id = invalid // straightforward assignment to a new value
// if we called a method we would be save, but how do we know that?
h.repo.save(c)
}
That somebody is able to use our code to do the above example should be terrifying.
Anyway, going back to domain events, where we want to serialize them. We can keep the fields private and then add a custom implementation of the MarshalJSON and UnmarshallJSON. That is something I recommend doing. Only that then we have to add a pointer receiver func (c *customerCreated) UnmarshalJSON(b []byte) error, mixed with a regular receiver func (c CustomerCreated) MarshalJSON() ([]byte, error) .
In this case, I do think it's worth the attempt on having the fields private. At least for domain events, and then make the marshall custom, also an advice from the book, is that if you have to add too much logic just to be able to marshall a struct, you'd better create a different struct for that, and keep the original with only the logic that belongs to it, and that's sound advice.
For aggregate root, I would try also to make its fields private, until I'd give up.
The rugged manifesto
You might wonder why I am being so picky about those things. This comes down to some principles that are very well stated in the Rugged Software Manifesto. The essence is that your code is going to be maintained by other people or by you in the future, so just make it easy for us! (or by content generations AIs which they'd better learn good coding standards from nice places on internet or we will have for real some unsolvable bugs!). It's an annoying word for non-native English speakers.
I also happen to think that the best way to be true to the rugged manifesto is to follow DDD principles together with some standard practices (architectural patterns and DevOps practices). The following images comes from CQRS by Example and shows those practices.
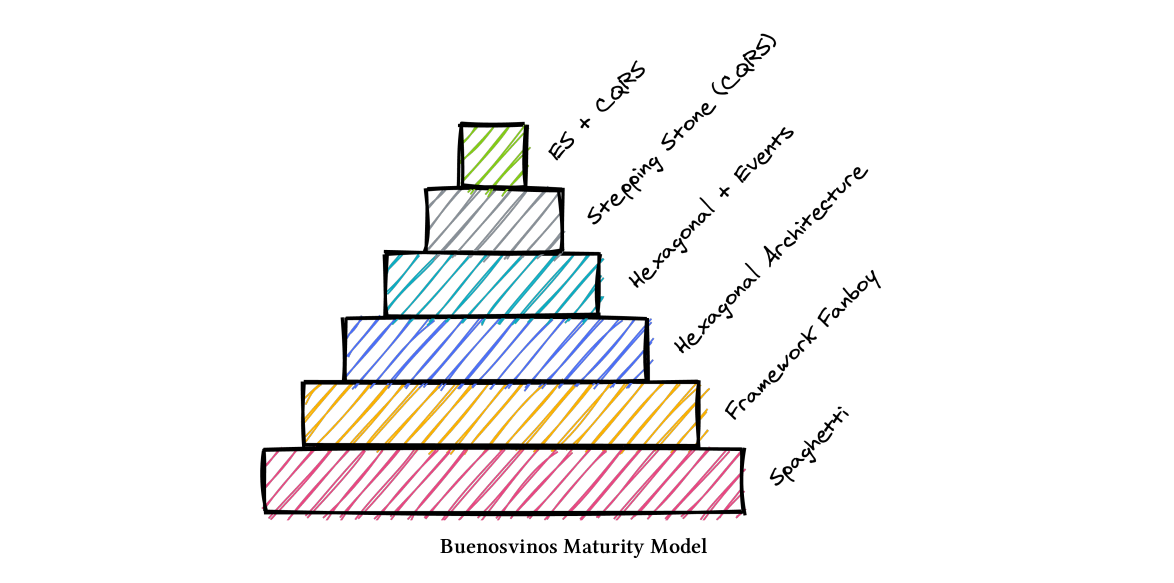
Being at the Hexagonal Architecture level should be a must for every developer. (Or call it Clean Architecture, or Onion architecture, they all have the same principle). No need to go beyond, but just above the framework fanboy.
You could argue that Go is not a language intended for such generic purposes like developing a regular API, where all the DDD patterns and the practices above apply. And it's more focused on low level projects closer to hardware. Libraries, OS stuff, bit processing. That is no reason to ditch all the good practices. You don't need DDD in order to make code with easy to understand interfaces.
Unfortunately, I have seen very little code out there that's not beyond framework fanboy. And which framework? you're going to ask me. There are no frameworks in Go! Well that's right, so everybody comes with its own, which is even worse. I am talking about code that is clean, can be read, but doesn't use any of the known patterns and follows some unwritten rules that you must learn while working on the project. Those rules are what makes the framework. And while some are widely spread in the whole community, like the returning error in the function as the second parameter, most are not, and apply solely on that project.
For example, when I was dealing with the problems above, I came across this video of a guy that has 40k subscribers. Since it didn't really solve my problems, I asked the question:

If 40k people are following the stop thinking advice, I wonder about their output...It seems that I am falling behind in a race to become the next framework fanboy.
So far the only place I could find good advice has been those 2 guys from Three Dots Labs that are writing the book Go With the Domain. I say writing because there are still empty chapters, but it's definitely worth a read. (Just be cautious, there's some weird modelling in there - an hour is very hard to defend as an entity, it should be a value object - that causes some weird code - GetOrCreateHour doesn't sound like a function that it should exist.)
The book seems like a recompilation of their blog articles, and it feels they've been through the same realization about the available information on internet about Go:
There are many tutorials showing some dumb ideas and claiming that they work without any evidence - let's don't trust them blindly!
Just to remind: if someone has a couple of thousand Twitter followers, that alone is not a reason to trust them!
And it has a reverence for the Accelerate book, and that's the reason I named this part the "rugged manifesto". I share the same principles, and so should you. As they say, it's based on scientific research. From Accelerate:
The rugged movement
Other names have been proposed to extend DevOps to cover infosec concerns.[...]. Another is Rugged DevOps, coined by Josh Corman and James Wickett. Rugged DevOps is the combination of DevOps with the Rugged Manifesto.
[Rugged manifesto]
For the Rugged movement to succeed-and in line with DevOps principles- being rugged is everybody's responsibility.
Final words
The whining here are just details compared to the big advantages that Go gives. If you're code compiles 99% sure that you have a good project. I was just very surprised that not many people struggled with the problem of I want to ensure that my code is going to be used the way I want it to be used instead of relying on prayers -or that they learn my custom framework- for that.
That's a principle of modular design: having a small interface and deep code. That's how you achieve a rich domain, and that's how you reduce complexity rather than adding to it. Go kind of undermines modular design by extending the surface anything you do more than it is desirable. So you have to resort on the assumption that future developers won't mess it, breaking the principle of the rugged manifesto.
I just have to assume that all GO developers know or will behave in a very specific way, so far I have:
We will always check for a constructor function and use them for types that are on other packages.
I will never cast primitives directly or indirectly to types found on other packages.
We will always deal with the error case (that's a good one)
We will access directly the fields of a struct -if they are public-, but we will never modify them, unless there are methods available, with a pointer receiver.
I just need to become comfortable with the above so I can find new Go ways to satisfy my coding standards.
Cheers!



