Self Hosted infrastructure on AWS with Terraform (part4)
The infrastructure pipeline

As I said like at least 10 times, this chapter will be focused on the pipeline and how to deploy to production. I read many books about DevOps, but one that I am missing (reading it currently) is the Continuous Delivery, which it could be called also "the pipeline". Anyway I assume many principles are shared among other books that the same co-author co-authored in other books that come from the same movement.
That is just a disclaimer, repeatedly stated among the series, that all of this could be better. Take this as the first iteration for our pipelines. It's probably a good approach, also a principle stated in the book (well that was on the first chapter, so I read that), to keep improving. It will be easier to improve if the starting point is simple and straightforward.
Thinking the pipeline
Our focus is to deploy everything to production. Production, in our case, means AWS. If you have followed the whole series, you know that we already can deploy to production using our own local machine! On each chapter we added bit of the Makefile to do precisely that:
plan-staging:
cd terraform/staging; export AWS_PROFILE=company-terraform; terraform init \
-backend-config="bucket=company-infra" \
-backend-config="key=infrastructure/staging/terraform.tfstate" \
-backend-config="region=eu-west-3"; \
terraform plan
plan-production:
cd terraform/production; export AWS_PROFILE=company-terraform; terraform init \
-backend-config="bucket=company-infra" \
-backend-config="key=infrastructure/production/terraform.tfstate" \
-backend-config="region=eu-west-3"; \
terraform plan
deploy-staging:
cd terraform/staging; export AWS_PROFILE=company-terraform; terraform init \
-backend-config="bucket=company-infra" \
-backend-config="key=infrastructure/staging/terraform.tfstate" \
-backend-config="region=eu-west-3"; \
terraform apply
deploy-production:
cd terraform/production; export AWS_PROFILE=company-terraform; terraform init \
-backend-config="bucket=company-infra" \
-backend-config="key=infrastructure/production/terraform.tfstate" \
-backend-config="region=eu-west-3"; \
terraform apply
I might have not said how picky Makefile is with tabs and spaces. You have to use tabs. Or spaces. I forgot which one. If you have an instruction that works, like "deploy-staging", just copy the empty spaces before the line and use that!
So we have that. We could call it a day! Well not yet! For one, this is not automatized. We have to execute this manually each time whenever we want to do a change. This is less than ideal. The other little thing is that this is in our machine. If we are the only person in our company -well, that's actually my case- that's not a problem. But as soon as other people wants to work in this project, how the hell are they gonna know what was the last thing deployed. How can this process be repeatable, reliable process? Even if they all use my laptop, it doesn't sound much reliable.
All of those are reasons for a pipeline. I am not going to insist much on that. It's quite common right? but nevertheless, a read to all of these books will be very worth it to understand more the why behind it (and probably a better how than what I am explaining here). Let's go more for business here.
Decisions and workflow
We need to put some though before starting. For example, I use Github to host all of my personal repositories, as well as professional-personal repositories. I am going to use Github workflows as my supporting platform for my pipeline. I don't want to start comparing all the possible options. Rule of thumb is to use whatever the place you use to host your repository offers. (On my super extensive experience about that, I get to know the big number of 3 of those platform, Github, Gitlab and Bitbucket, and they offer pretty much the same).
Use Github actions.
We have been working on two environments so far, I have called them staging and production. (Staging is a pre-production environment). We need to do also releases then to this other environment. And we also have a third environment, independent, which is the global environment.
A straightforward decision then is the following:
Develop branch changes will trigger deploys to the staging environment and Main branch changes will trigger deploys to both productions and global environment.
With this workflow:
The workflow is to develop on the develop branch (...) and then merge to the main branch.
There are some issues with this workflow, let me first explain them, but I am happy enough that you are only aware of those issues. So you can act when appropriately. Remember that this is a context of a small business, you are probably working alone, and there's no need to over complicate things. We are having a simple pipeline, small, easy to change and easy to modify, when those issues become and actual problem.
So which issues do we have? First is that this workflow is not enforced by the code, and this is something that I am going to completely ignore. While I would like to force a single way of working, chances are that I want to change it sooner than later, so I'll count on developer discipline before adding some obstacles that I would like to remove later.
The other issue is that, if we don't enforce that, the develop branch can evolve on its own and we can have many different things between staging and production environment. We have the case where we actually want to have different stuff on our staging and production environments. After all, we have different main.tf files for these two environments. Both things together make a little bit of code smell, should it be maybe two independent repositories? Let's ignore it for now, and, again, let's rely on developer discipline on this. We will see how we want to evolve.
For now, we can assume that whatever it's on main branch production/main.tf and global.tf is what's on production, and also for staging/main.tf unless we did some development on the develop branch not yet merged to the main branch.
The third issue, and this one we are going to act a little bit on it, is that we don't have tests. The only thing we have is that 'cautious' deploy to staging first. Which, if you count that as test, then it's anti-devops, count it for just a way to have staging environment the way we want. This is not a fast, reliable, automated release, it's an automated deploy, but with manual test to check that works all right.
We need real tests, and preferably in a step before integrating our code. What's our continuous integration? Following our workflow, our integrations is the actual merge from develop to master. As long as we run some tests prior to that, we are slightly on the higher terrain. Infrastructure tests are hard. On this book you can get started. On our case, we will consider a lame terrafrom plan that is passing as our test. We will execute everywhere.
Summarizing it all, we need a pipeline to run the "tests" that is triggered all the time, and then a couple more to deploy to staging and to production.
| Code | Test (plan) trigger | Release trigger (plan+apply) |
|---|---|---|
| staging/main.tf | any change | Change on develop branch |
| production/main.tf | any change | Change on main branch |
| global/main.tf | any change | Change on main branch |
Cheating: I am not putting much attention to the global/main.tf, but as you know, this bit of infrastructure needs to be deployed prior to deploying production AND staging. This bit of infrastructure is also the most static one, it's rarely gonna change. What I did is that I executed it first, from my local, already. The proper way is to think about it and put a proper pipeline in place. I just went fast, straightforward, and once I had it executed, I added as part of the production pipeline, and that's good enough.
We know it's not the perfect solution but it's a fast solution and a working solution, so let's implement it.
Configuring the pipelines
Staging
Let's create the staging pipeline. The way Github works is by adding a hidden folder called "github" and there we add a directory called "workflows" (better check the real documentation). Inside you can define all of your jobs.
├── .github
│ └── workflows
│ ├── apply-staging.yml
Create this file and start and add the first lines to specify when the jobs we are going to write are going to be triggered.
name: Apply terraform changes to staging
on:
push:
branches:
- develop
I am assuming we are going to work on our local machine, and then eventually push the develop branch with our changes. That might work also if we worked in a specific branch and then merged to develop using Github buttons (I am not 100% sure). In general, I avoid using web user interfaces for things that can be done using code, - IaC, git commands- but I can do exceptions if we had to follow a workflow, like, merging to main can only happen trough github web page...
This is all we need to do to release to staging:
jobs:
update-infra-staging:
runs-on: ubuntu-latest
steps:
- name: Check out repository code
uses: actions/checkout@v2
- run: echo "💡 The ${{ github.repository }} repository has been cloned to the runner."
- uses: actions/checkout@v1
- uses: actions/checkout@v2
- id: EniltrexAction
uses: eniltrexAdmin/install-terraform-github-action@v1.0.3
with:
version: '1.0.6'
working-directory: 'install-terraform'
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_TERRAFORM_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_TERRAFORM_KEY_SECRET }}
aws-region: eu-west-3
- name: Terraform apply
working-directory: terraform/staging
run: |
terraform init -backend-config="bucket=company-infra" \
-backend-config="key=infrastructure/staging/terraform.tfstate" \
-backend-config="region=eu-west-3"
terraform plan -out=tfplan -input=false
terraform apply -input=false tfplan
This is basically the translation from the Makefile to a github action. The job checks out the code, installs terraform in the machine, sets the amazon credentials and executes terraform apply from the previous plan.
Explaining this better, it's like having a machine for you (paid by github). The machine though won't do anything unless you tell it what to do. The job is what you want the machine to do. You have to make sure though that the machine will be able to do everything you want it to do. That's why we need to install terraform in the machine, also to check out the code (meaning doing a git clone of our code on that specific commit that the job has been triggered from), and setting up some credentials so the final instruction, the terraform init, plan and apply can be properly executed.
You may think that there's already a single github action that does all of that at once. Why don't I use it? Because I like to understand things. You see what I am doing is almost 1-to-1 translation from the our Makefile. What's the advantage of understanding things? You can change them faster, or fix them when they fail. Also, in this case, it's quite fast to just add this 4 actions. If it were something very annoying to write or long, I might consider it more, but it's just a very small extra effort to have something that follows the KISS principle.
I hope the way of using this job is quite self explainable. If you have doubts, check the official documentation. Also, on how to set 'secrets' on your repository that the pipeline can use. We have two in our case: ${{ secrets.AWS_TERRAFORM_KEY_ID }} ${{ secrets.AWS_TERRAFORM_KEY_SECRET }}
Those are the keys for the user that has enough permissions to deploy the whole infra. The one that I call "company-terraform", and you will have the credentials ready on your ~/.aws/credentials if you have followed the whole tutorial.
Make sure you use the same backend config as in the Makefile. When you have more people in your company, you might want to add a lock logic with the state file. Terraform gives you that out of the box with little extra effort (the effort I have to make to check it out). Right now it's not an issue if you are the only one executing this action.
You may wonder why I went through the hustle to create a github action for installing terraform while there are already specific ones for that. Well, as I explain in the readme, the most common action available out there has the problem that I doesn't allow to have a directory in the root of the project that is called "terraform". And I totally want to. And before changing the name of the directory, I decided to create a github action that suited my needs. (You are to judge whether that was smart or not...)
"Testing"
As explained before, we don't have actually testing, in our case it's just gonna be planning, this is preparing for more sophisticated testing, we just have the pipeline for that, which looks like this:
name: Plan terraform changes on all env
on:
push:
jobs:
plan-infra-staging:
runs-on: ubuntu-latest
steps:
- name: Check out repository code
uses: actions/checkout@v2
- run: echo "💡 The ${{ github.repository }} repository has been cloned to the runner."
- uses: actions/checkout@v1
- uses: actions/checkout@v2
- id: EniltrexAction
uses: eniltrexAdmin/install-terraform-github-action@v1.0.3
with:
version: '1.0.6'
working-directory: 'install-terraform'
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_TERRAFORM_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_TERRAFORM_KEY_SECRET }}
aws-region: eu-west-3
- name: Terraform plan
working-directory: terraform/staging
run: |
terraform init -backend-config="bucket=company-infra" \
-backend-config="key=infrastructure/staging/terraform.tfstate" \
-backend-config="region=eu-west-3"
terraform plan -out=tfplan -input=false
plan-infra-production:
runs-on: ubuntu-latest
steps:
- name: Check out repository code
uses: actions/checkout@v2
- run: echo "💡 The ${{ github.repository }} repository has been cloned to the runner."
- uses: actions/checkout@v1
- uses: actions/checkout@v2
- id: EniltrexAction
uses: eniltrexAdmin/install-terraform-github-action@v1.0.3
with:
version: '1.0.6'
working-directory: 'install-terraform'
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_TERRAFORM_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_TERRAFORM_KEY_SECRET }}
aws-region: eu-west-3
- name: Terraform plan
working-directory: terraform/production
run: |
terraform init -backend-config="bucket=company-infra" \
-backend-config="key=infrastructure/production/terraform.tfstate" \
-backend-config="region=eu-west-3"
terraform plan -out=tfplan -input=false
plan-infra-global:
runs-on: ubuntu-latest
steps:
- name: Check out repository code
uses: actions/checkout@v2
- run: echo "💡 The ${{ github.repository }} repository has been cloned to the runner."
- uses: actions/checkout@v1
- uses: actions/checkout@v2
- id: EniltrexAction
uses: eniltrexAdmin/install-terraform-github-action@v1.0.3
with:
version: '1.0.6'
working-directory: 'install-terraform'
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_TERRAFORM_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_TERRAFORM_KEY_SECRET }}
aws-region: eu-west-3
- name: Terraform plan
working-directory: terraform/global
run: |
terraform init -backend-config="bucket=company-infra" \
-backend-config="key=infrastructure/global/terraform.tfstate" \
-backend-config="region=eu-west-3"
terraform plan -out=tfplan -input=false
It's basically a copy paste of the 4 jobs above, with only terraform plan instead of terraform apply. For all the environments.
Deploying to production
The deploy to production will look like this.
name: Apply terraform changes to PRODUCTION
on:
push:
branches:
- main
jobs:
update-infra-production:
runs-on: ubuntu-latest
steps:
- name: Check out repository code
uses: actions/checkout@v2
- run: echo "💡 The ${{ github.repository }} repository has been cloned to the runner."
- uses: actions/checkout@v1
- uses: actions/checkout@v2
- id: EniltrexAction
uses: eniltrexAdmin/install-terraform-github-action@v1.0.3
with:
version: '1.0.6'
working-directory: 'install-terraform'
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_TERRAFORM_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_TERRAFORM_KEY_SECRET }}
aws-region: eu-west-3
- name: Terraform apply
working-directory: terraform/production
run: |
terraform init -backend-config="bucket=company-infra" \
-backend-config="key=infrastructure/production/terraform.tfstate" \
-backend-config="region=eu-west-3"
terraform plan -out=tfplan -input=false
terraform apply -input=false tfplan
update-infra-global:
runs-on: ubuntu-latest
steps:
- name: Check out repository code
uses: actions/checkout@v2
- run: echo "💡 The ${{ github.repository }} repository has been cloned to the runner."
- uses: actions/checkout@v1
- uses: actions/checkout@v2
- id: EniltrexAction
uses: eniltrexAdmin/install-terraform-github-action@v1.0.3
with:
version: '1.0.6'
working-directory: 'install-terraform'
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_TERRAFORM_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_TERRAFORM_KEY_SECRET }}
aws-region: eu-west-3
- name: Terraform apply
working-directory: terraform/global
run: |
terraform init -backend-config="bucket=company-infra" \
-backend-config="key=infrastructure/global/terraform.tfstate" \
-backend-config="region=eu-west-3"
terraform plan -out=tfplan -input=false
terraform apply -input=false tfplan
It's just the same as deploying to staging, with the added job of deploying global.
The pipeline in action
Once you have all of those files written and committed in your version control, if you go to your github repository, on the actions tab you will see a list of your workflows - execution of pipelines- that were executed:

If you merge something to main (or by bypassing the workflow you push to main directly, that hey! that's another reasons I am using this pipeline, room to wiggle and to be lax - until there's some problems and then we become more strict and force by code or options to use a specific way of triggering the pipeline)
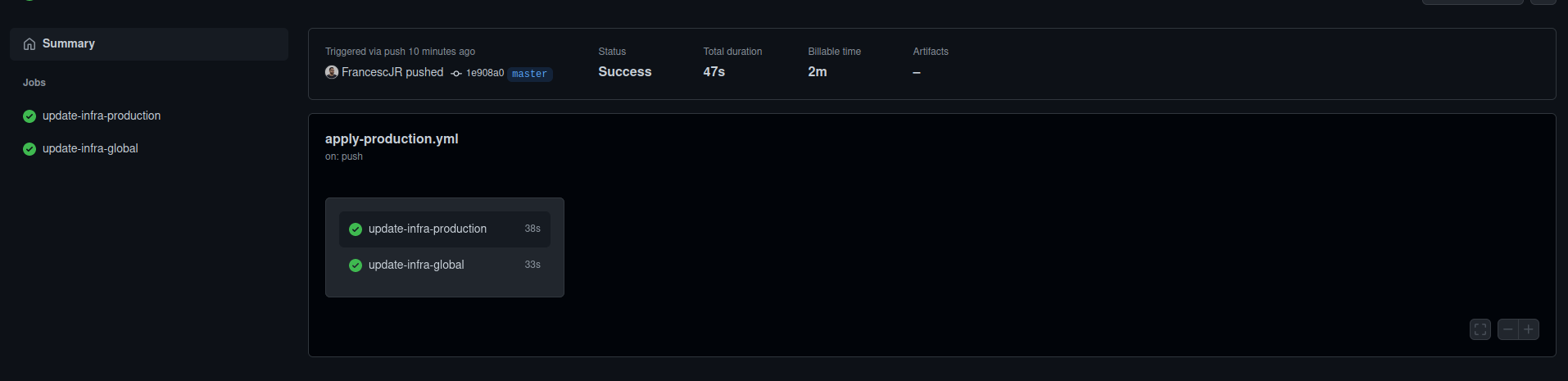
And if you click inside, you will see all of the jobs that have been run.
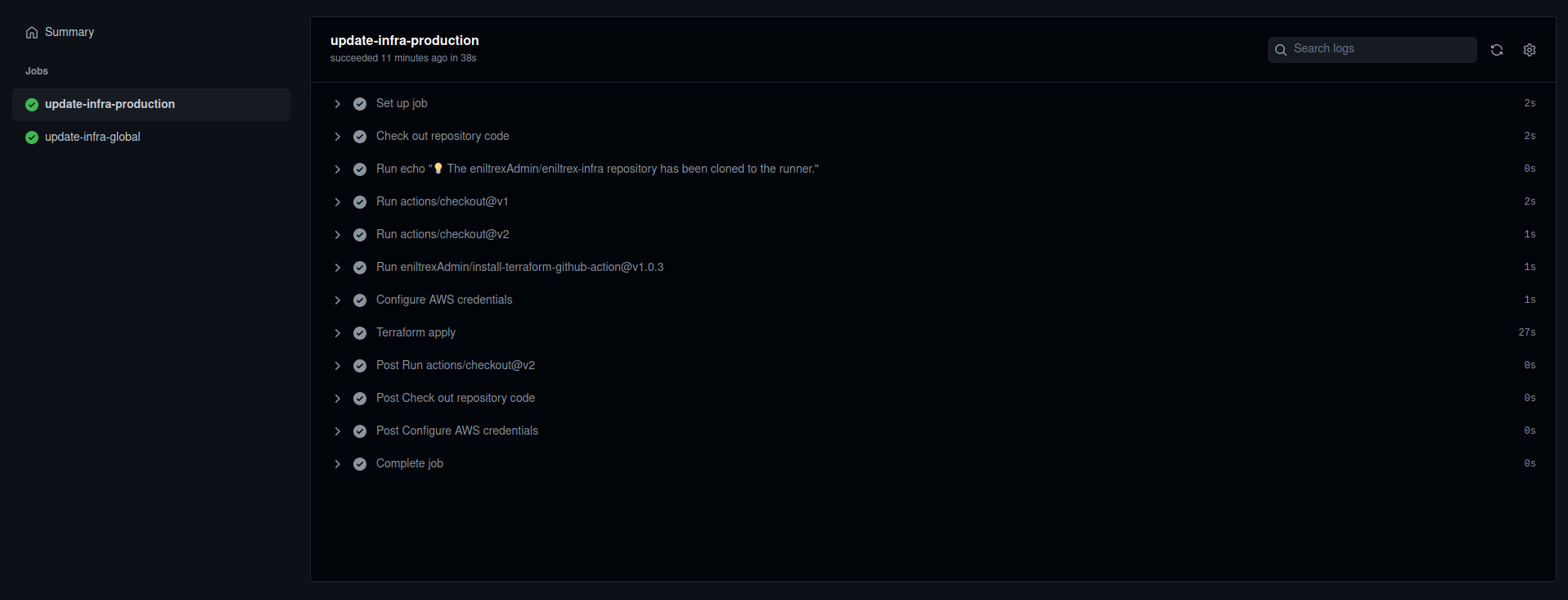
Congratulations! You have a production environment ready as soon as you have your main branch ready, without having to think about it! Unless when it breaks, but that's also the point, the first thing you will do will be fixing the problem so it doesn't break anymore!
This is a simple approach, but as soon as something fails you will receive an email. It will also force you to make the plan pass before pushing anything. There's also room to wiggle, not that I like it, but let's not overthink stuff too much at this stage. This is the first approach and as soon as we encounter problems, we will react on it, being by forcing some way of working and forbidding another, or adding a test that checks that specific error that we just encountered, or others. From here we grow.
Upcoming
Stay tuned for the final part of this "season", where I explain the pipeline on the React project. hopefully I will speak less about the why behind the pipeline and I will start more for business. It will be a short one, I promise.
Then I will take a break from this series to focus on the CQRS+ES series, many interesting things to explain and to discuss over there. Then I will come back on this series, to deploy Go projects with lambda and API GW. Another module that you might want to make it your own and use it and modify it as you please.



